Agenta
Agenta centralizes LLMOps to accelerate reliable AI development and boost team productivity.
Visit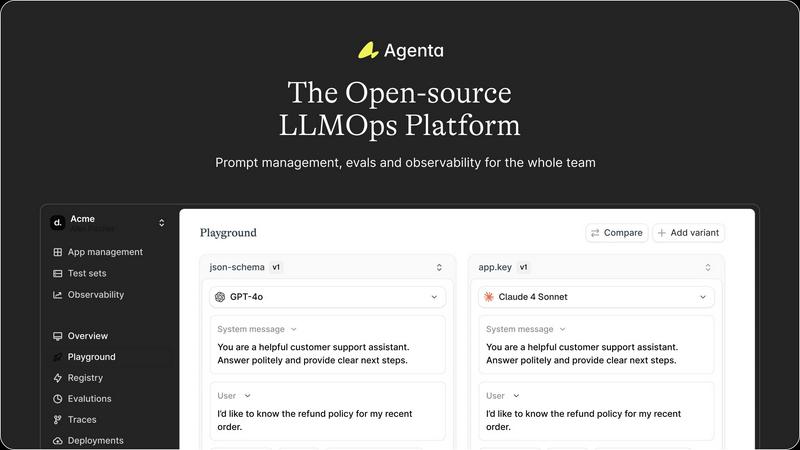
About Agenta
Agenta is an enterprise-grade, open-source LLMOps platform engineered to solve the critical organizational and technical challenges faced by AI development teams building with large language models. In a landscape where LLMs are inherently unpredictable, Agenta provides the essential infrastructure to transform chaotic, error-prone workflows into structured, reliable, and collaborative processes. The platform serves as a single source of truth for cross-functional teams, including developers, product managers, and domain experts, enabling them to centralize prompt management, conduct systematic evaluations, and gain full observability into their AI systems. By integrating these capabilities into one cohesive environment, Agenta directly addresses the inefficiencies of scattered prompts across communication tools and siloed team efforts. The core value proposition is clear: empower organizations to ship high-quality, reliable LLM applications faster by minimizing guesswork, reducing debugging time, and providing the evidence-based framework needed for continuous improvement and confident deployment.
Features of Agenta
Unified Playground & Version Control
Agenta provides a centralized playground where teams can experiment with different prompts, parameters, and foundation models from various providers in a side-by-side comparison view. This model-agnostic approach prevents vendor lock-in. Every iteration is automatically versioned, creating a complete audit trail of changes. This feature eliminates the chaos of managing prompts across disparate documents and ensures that any experiment or production configuration can be precisely tracked, replicated, or rolled back, fostering disciplined experimentation.
Automated & Human-in-the-Loop Evaluation
The platform replaces subjective "vibe testing" with a systematic evaluation framework. Teams can integrate LLM-as-a-judge evaluators, custom code, or built-in metrics to automatically assess performance. Crucially, Agenta supports full-trace evaluation for complex agents, testing each reasoning step, not just the final output. It seamlessly incorporates human feedback from domain experts into the evaluation workflow, turning qualitative insights into quantitative evidence for decision-making before any deployment.
Production Observability & Debugging
Agenta offers comprehensive observability by tracing every LLM application request in production. This allows teams to pinpoint exact failure points in complex chains or agentic workflows. Any problematic trace can be instantly annotated by the team or flagged by users and converted into a test case with a single click, closing the feedback loop. Live monitoring and online evaluations help detect performance regressions in real-time, ensuring system reliability.
Cross-Functional Collaboration Hub
Agenta breaks down silos by providing tailored interfaces for every team member. Domain experts can safely edit and experiment with prompts through a dedicated UI without writing code. Product managers and experts can directly run evaluations and compare experiments. With full parity between its API and UI, Agenta integrates both programmatic and manual workflows into one central hub, aligning technical and business stakeholders on a unified LLMOps process.
Use Cases of Agenta
Streamlining Enterprise Chatbot Development
Development teams building customer-facing or internal support chatbots use Agenta to manage hundreds of prompt variations for different intents and scenarios. Product managers and subject matter experts collaborate directly in the platform to refine responses based on real user interactions. Automated evaluations against quality and safety test sets ensure each new prompt version is an improvement before being promoted, drastically reducing rollout cycles and improving answer consistency.
Building and Auditing Complex AI Agents
For teams developing multi-step AI agents involving reasoning, tool use, and retrieval, Agenta is critical for debugging and evaluation. The full-trace observability allows engineers to see exactly where in an agent's chain a failure occurred. They can save these errors as test cases and use the playground to iteratively fix issues. Systematic evaluation of each intermediate step ensures the entire agentic workflow is robust, not just its individual components.
Managing LLM Application Lifecycle for Product Teams
Cross-functional product teams use Agenta as their central LLM lifecycle management platform. From the initial prompt experimentation phase, through rigorous evaluation with business-defined metrics, to post-deployment monitoring, all activities are coordinated in one system. This end-to-end visibility enables data-driven decisions, ensures compliance with internal standards, and provides a clear audit trail for all changes made to the AI application.
Rapid Prototyping and A/B Testing LLM Features
When integrating new LLM-powered features into an existing product, Agenta accelerates the prototyping phase. Developers can quickly test different models and prompts using the unified playground. Teams can then design and run scalable A/B tests (online evaluations) directly within Agenta, comparing the performance of different experimental variants in a live environment with real user data to determine the optimal configuration with statistical confidence.
Frequently Asked Questions
Is Agenta truly model and framework agnostic?
Yes, Agenta is designed to be fully agnostic. It seamlessly integrates with any major LLM provider (OpenAI, Anthropic, Cohere, open-source models, etc.) and supports popular development frameworks like LangChain and LlamaIndex. This architecture prevents vendor lock-in, allowing your team to use the best model for each specific task and switch providers as needed without overhauling your entire MLOps pipeline.
How does Agenta facilitate collaboration with non-technical team members?
Agenta provides specialized user interfaces that empower product managers and domain experts. These stakeholders can directly access the playground to edit prompts, create evaluation test sets from production errors, and run comparison experiments—all without writing or interacting with code. This bridges the gap between technical implementation and business expertise, ensuring the AI product is shaped by those who understand the domain best.
Can we use our own custom metrics and evaluators?
Absolutely. While Agenta offers built-in evaluators and supports the LLM-as-a-judge pattern, it is built for extensibility. Teams can integrate their own custom code evaluators to implement proprietary business logic, compliance checks, or domain-specific quality metrics. This flexibility ensures your evaluation suite measures what truly matters for your specific application and success criteria.
How does the observability feature aid in debugging complex failures?
Agenta captures the complete trace of every LLM call, including inputs, outputs, intermediate steps, and tool executions in an agentic workflow. When a failure occurs, developers are not left guessing; they can drill down into the exact step where the error originated. This granular visibility transforms debugging from a time-consuming investigation into a precise and efficient process, significantly reducing mean time to resolution (MTTR).
Explore more in this category:
Similar to Agenta
MCPize is a marketplace where developers can discover, install, and manage 1,000+ premium MCP servers while publishers keep 80% of revenue.
Deploy secure AI agents across your enterprise with Agyn's open-source platform that delivers top SWE-bench performance and least-privilege access.
act101 is an enterprise AI agent tool with 163 grammars that refactors and ports code across languages, reducing token usage by 85% while keeping.
Capture high-quality screenshots from any URL instantly with BoltShot's ultra-fast API, enhancing productivity for developers and marketers alike.
ButterKit accelerates app store localization workflows by automating multilingual screenshot and metadata creation to boost global conversion rates.
Headless Domains provides AI agents with secure, verifiable identities to enhance trust and streamline interactions across platforms.