Fallom vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
Fallom delivers real-time observability for LLMs, enhancing tracking, debugging, and cost management for AI operations.
Last updated: February 28, 2026
OpenMark AI benchmarks 100+ LLMs on your task: cost, speed, quality & stability. Browser-based; no provider API keys for hosted runs.
Visual Comparison
Fallom
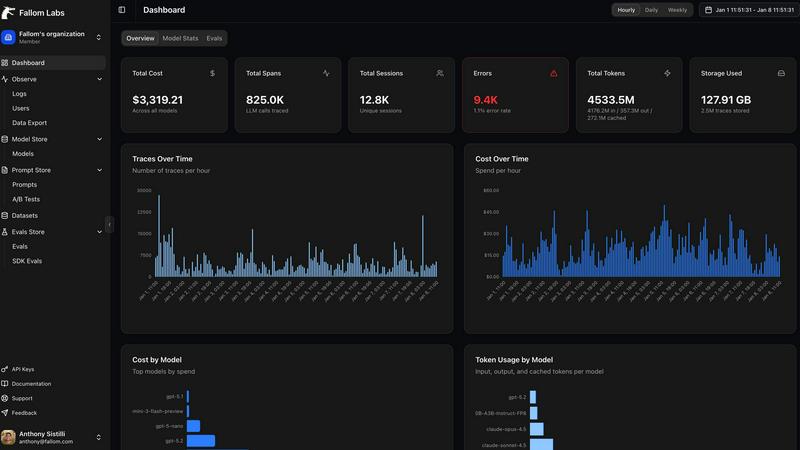
OpenMark AI

Overview
About Fallom
Fallom is a cutting-edge AI-native observability platform specifically designed to enhance the performance and management of large language models (LLMs) and agent workloads. By offering organizations unparalleled visibility into every LLM call made in production, Fallom enables comprehensive end-to-end tracing that includes critical components such as prompts, outputs, tool calls, tokens, latency, and cost per call. This platform is tailored for businesses requiring robust observability tools to navigate the complexities of AI operations, ensuring that teams can monitor usage in real-time, debug issues swiftly, and effectively allocate spending across various models, users, and teams. Additionally, Fallom provides essential session, user, and customer-level context, which is particularly vital for organizations operating in regulated environments. This includes delivering enterprise-ready audit trails, logging, model versioning, and consent tracking to meet compliance standards. With a single OpenTelemetry-native SDK, teams can instrument their applications within minutes, making Fallom an indispensable tool for organizations aiming to boost their LLM operational efficiency and compliance readiness.
About OpenMark AI
OpenMark AI is a web application for task-level LLM benchmarking. You describe what you want to test in plain language, run the same prompts against many models in one session, and compare cost per request, latency, scored quality, and stability across repeat runs, so you see variance, not a single lucky output.
The product is built for developers and product teams who need to choose or validate a model before shipping an AI feature. Hosted benchmarking uses credits, so you do not need to configure separate OpenAI, Anthropic, or Google API keys for every comparison.
You get side-by-side results with real API calls to models, not cached marketing numbers. Use it when you care about cost efficiency (quality relative to what you pay), not just the cheapest token price on a datasheet.
OpenMark AI supports a large catalog of models and focuses on pre-deployment decisions: which model fits this workflow, at what cost, and whether outputs are consistent when you run the same task again. Free and paid plans are available; details are shown in the in-app billing section.