Friendli Engine
About Friendli Engine
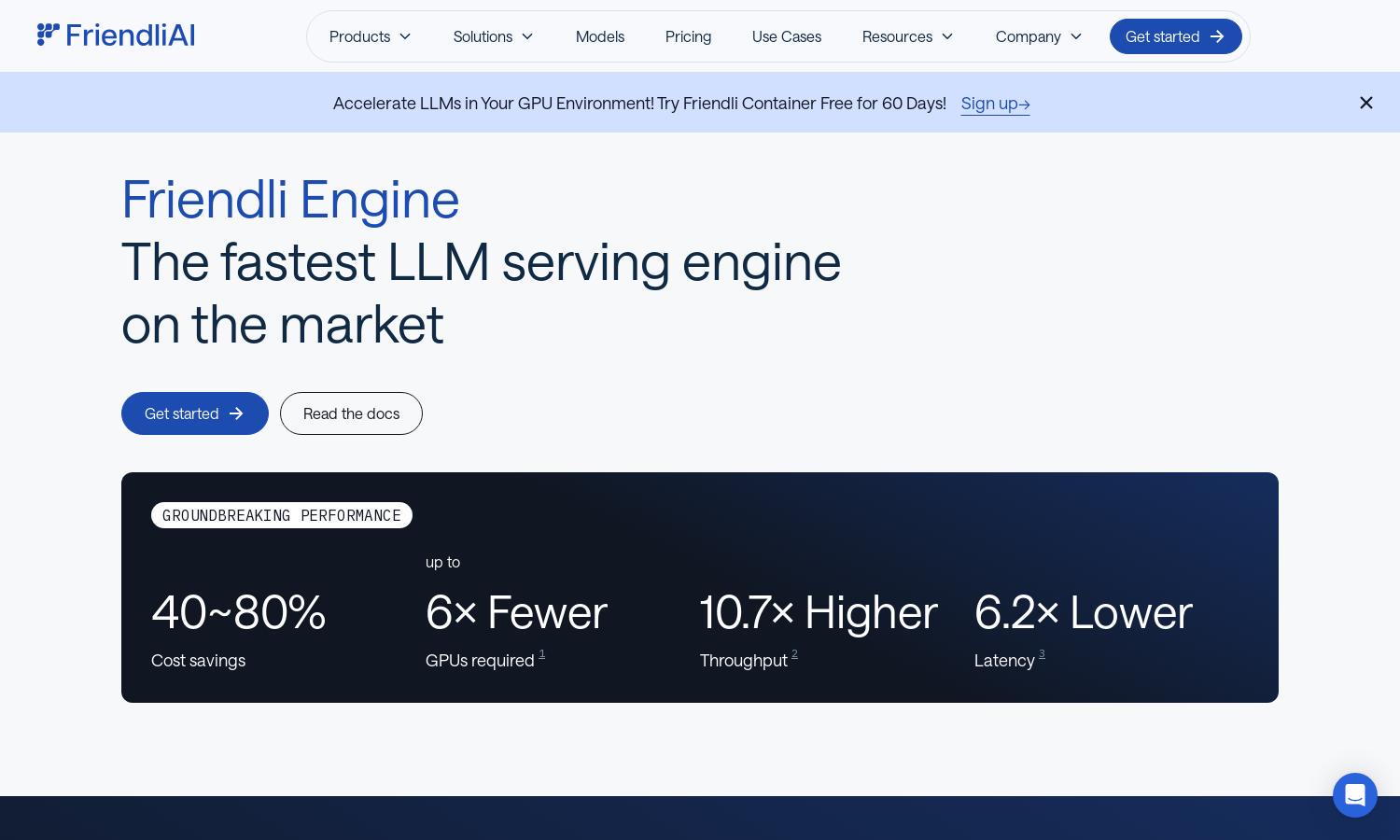
Friendli Engine is an innovative platform that accelerates LLM inference, making generative AI models faster and more cost-effective. With patent-protected technologies like iteration batching and speculative decoding, it allows users to seamlessly deploy LLMs while enhancing customization and efficiency, catering to businesses and AI developers.
Friendli Engine offers flexible pricing plans tailored for different user needs. Each tier provides access to advanced features, including optimized GPU performance and support for multiple models. Users benefit from cost efficiencies and enhanced capabilities, with upgrades unlocking greater performance potential for demanding applications.
Friendli Engine features an intuitive user interface designed for seamless interaction. Its layout facilitates easy navigation between various functionalities, from model serving to analytics, ensuring a pleasant user experience. Unique features enhance usability, making it an accessible tool for developers and businesses in generative AI.
How Friendli Engine works
Users begin by signing up for Friendli Engine and selecting their preferred deployment option, such as Dedicated Endpoints or Container services. They easily upload their LLM models or choose from existing ones, leveraging optimized GPU capabilities. The platform's user-friendly interface supports navigation through model tuning, concurrent request processing, and performance metrics to enhance efficiency and reduce costs.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine utilizes unique iteration batching technology that significantly enhances LLM inference throughput. This innovative approach allows users to manage multiple generation requests more effectively, delivering up to tens of times higher performance compared to conventional methods, making it a standout feature for efficient model serving.
Multi-LoRA Serving
Multi-LoRA serving on Friendli Engine allows simultaneous use of multiple LoRA models on fewer GPUs, even a single one. This groundbreaking feature simplifies LLM customization, significantly reduces hardware costs, and enhances accessibility for developers looking to maximize their model deployment potential.
Friendli TCache
The Friendli TCache system intelligently stores and reuses frequent computational results, drastically reducing GPU workload. This feature optimizes Time to First Token (TTFT), delivering speeds up to 23 times faster than competing systems. It exemplifies Friendli Engine's commitment to efficiency and performance in LLM inference.
You may also like: